5장. Scanpy를 이용한 단일세포 데이터 분석
5.1 단일세포 분석이란?
전통적인 bulk RNA-seq은 수천~수백만 개의 세포를 한꺼번에 분석하여 평균적인 유전자 발현을 측정한다. 반면, 단일세포 RNA-seq(scRNA-seq)은 개별 세포 하나하나의 유전자 발현을 측정한다.
이를 통해 다음과 같은 질문에 답할 수 있다:
- 이 조직에는 어떤 종류의 세포들이 있는가?
- 각 세포 유형의 비율은 어떻게 되는가?
- 특정 질환에서 어떤 세포 유형이 변화하는가?
Scanpy는 이러한 단일세포 데이터를 분석하기 위한 Python 패키지이다.
5.2 패키지 설치
pip install scanpy anndata mudata- scanpy: 단일세포 분석의 핵심 패키지
- anndata: h5ad 파일 형식을 다루는 패키지
- mudata: h5mu 파일(멀티오믹스 데이터)을 다루는 패키지
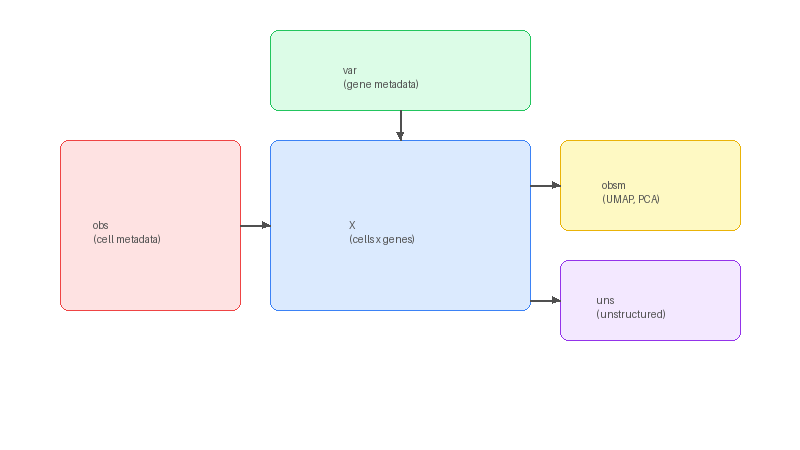
5.3 AnnData — 단일세포 데이터 구조
h5ad 파일이란?
h5ad는 단일세포 데이터의 표준 저장 형식이다. HDF5 기반으로, 대용량 데이터를 효율적으로 저장하고 읽을 수 있다.
하나의 h5ad 파일에는 다음 정보가 모두 담겨 있다:
| 속성 | 설명 | 예시 |
|---|---|---|
X |
유전자 발현 매트릭스 (세포 × 유전자) | 10,000 세포 × 20,000 유전자 |
obs |
세포(행)에 대한 메타데이터 | cell_type, sample_id, condition |
var |
유전자(열)에 대한 메타데이터 | gene_name, highly_variable |
obsm |
세포의 임베딩 좌표 | UMAP, t-SNE, PCA 좌표 |
uns |
비구조화 데이터 | 색상 팔레트, 분석 파라미터 |
기본 사용법
import scanpy as sc
import anndata as ad
# h5ad 파일 읽기
adata = sc.read_h5ad("pbmc_10k.h5ad")
# 데이터 구조 확인
print(adata)
# AnnData object with n_obs × n_vars = 10000 × 20000
# obs: 'cell_type', 'sample', 'condition'
# var: 'gene_name', 'highly_variable'
# obsm: 'X_pca', 'X_umap'
# 세포 메타데이터 확인 (pandas DataFrame)
adata.obs.head()
# 유전자 메타데이터 확인
adata.var.head()
# 특정 세포 유형만 선택
t_cells = adata[adata.obs["cell_type"] == "T cell"]
# 특정 유전자의 발현량 확인
adata[:, "CD3E"].X.toarray()AI에게 요청하는 예시
“pbmc_10k.h5ad 파일을 읽어서 어떤 cell_type이 있는지, 각 유형별 세포 수를 보여줘”
5.4 MuData — 멀티오믹스 데이터
h5mu 파일이란?
h5mu는 멀티오믹스 데이터를 저장하는 형식이다. 하나의 파일에 여러 종류의 데이터(예: RNA + ATAC, RNA + Protein)를 함께 담을 수 있다.
import mudata as md
# h5mu 파일 읽기
mdata = md.read_h5mu("multiome.h5mu")
# 어떤 modality가 포함되어 있는지 확인
print(mdata.mod)
# {'rna': AnnData object with n_obs × n_vars = 5000 × 20000,
# 'atac': AnnData object with n_obs × n_vars = 5000 × 100000}
# 개별 modality 접근
rna = mdata.mod["rna"] # RNA 데이터 (AnnData)
atac = mdata.mod["atac"] # ATAC 데이터 (AnnData)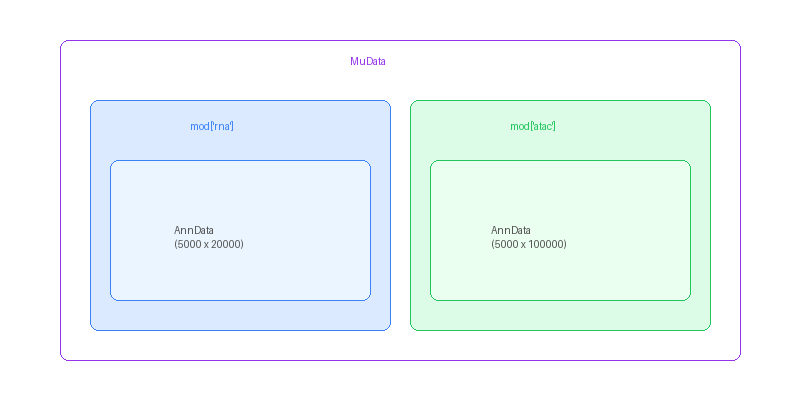
5.5 Scanpy 분석 워크플로우
단일세포 분석은 보통 다음 순서로 진행된다:
1단계: 품질 관리 (Quality Control)
# 미토콘드리아 유전자 비율 계산
adata.var["mt"] = adata.var_names.str.startswith("MT-")
sc.pp.calculate_qc_metrics(adata, qc_vars=["mt"], inplace=True)
# QC 시각화
sc.pl.violin(adata, ["n_genes_by_counts", "total_counts", "pct_counts_mt"])
# 품질이 낮은 세포 제거
adata = adata[adata.obs["n_genes_by_counts"] > 200]
adata = adata[adata.obs["pct_counts_mt"] < 20]2단계: 정규화 및 전처리
# 정규화
sc.pp.normalize_total(adata, target_sum=1e4)
sc.pp.log1p(adata)
# 고변동 유전자 선택
sc.pp.highly_variable_genes(adata, n_top_genes=2000)
sc.pl.highly_variable_genes(adata)3단계: 차원 축소
# PCA
sc.tl.pca(adata)
sc.pl.pca_variance_ratio(adata, n_pcs=50)
# 이웃 그래프 구축 + UMAP
sc.pp.neighbors(adata, n_pcs=30)
sc.tl.umap(adata)4단계: 클러스터링
# Leiden 클러스터링
sc.tl.leiden(adata, resolution=0.5)
# UMAP에 클러스터 표시
sc.pl.umap(adata, color="leiden")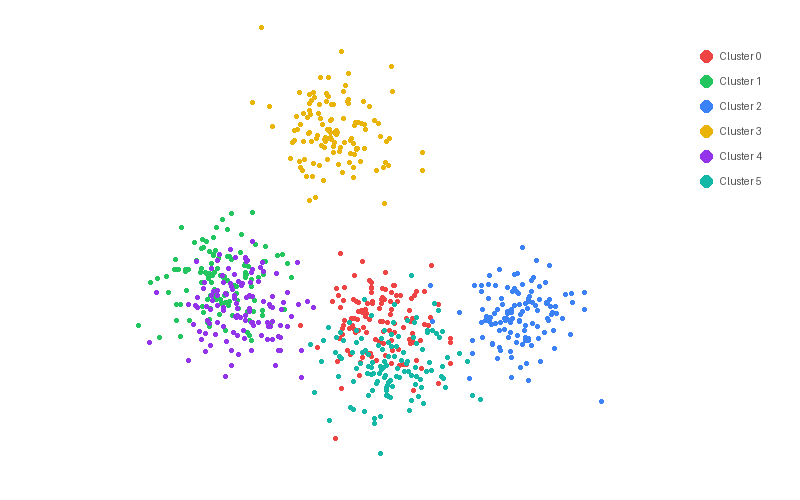
5단계: 세포 유형 주석
# 클러스터별 마커 유전자 확인
sc.tl.rank_genes_groups(adata, groupby="leiden")
sc.pl.rank_genes_groups(adata, n_genes=10)
# 특정 마커 유전자로 UMAP 시각화
sc.pl.umap(adata, color=["CD3E", "CD14", "MS4A1", "NKG7"])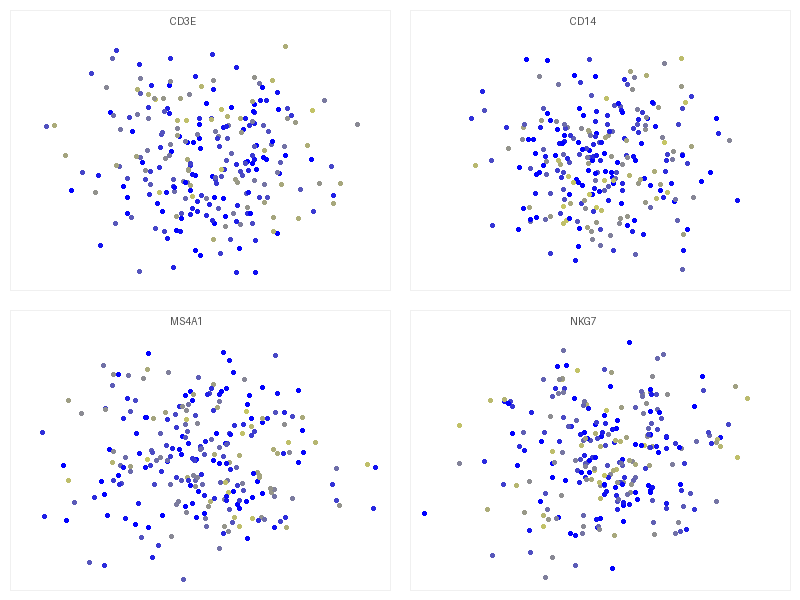
6단계: 결과 저장
# h5ad 파일로 저장
adata.write_h5ad("pbmc_analyzed.h5ad")5.6 바이브 코딩으로 단일세포 분석하기
실전 대화 예시
단일세포 분석의 전체 과정을 AI와 대화하며 진행할 수 있다:
사용자: “pbmc_10k.h5ad 파일을 읽고 QC 해줘. 미토콘드리아 비율 20% 이상, 유전자 수 200개 미만인 세포는 제거해줘”
사용자: “정규화하고 고변동 유전자 2000개 선택해서 PCA, UMAP 해줘”
사용자: “Leiden 클러스터링 해주고, 각 클러스터의 마커 유전자 상위 5개씩 보여줘”
사용자: “CD3E, CD14, MS4A1, NKG7 마커로 봤을 때 각 클러스터가 어떤 세포 유형인지 UMAP에 표시해줘”
알아야 할 핵심 개념
코드를 외울 필요는 없지만, AI에게 올바른 지시를 내리려면 다음 개념들을 이해해야 한다:
| 개념 | 설명 |
|---|---|
| QC (Quality Control) | 품질이 낮은 세포를 걸러내는 과정 |
| 정규화 (Normalization) | 세포 간 시퀀싱 깊이 차이를 보정 |
| 고변동 유전자 (HVG) | 세포 간 발현 차이가 큰 유전자. 분석의 핵심 |
| PCA | 고차원 데이터를 주요 성분으로 압축 |
| UMAP | 고차원 데이터를 2D로 시각화 |
| 클러스터링 | 유사한 세포를 그룹으로 묶는 과정 |
| 마커 유전자 | 특정 세포 유형을 구분하는 유전자 |
5.7 정리
- h5ad: 단일세포 데이터의 표준 파일 형식. 발현 매트릭스, 세포/유전자 메타데이터, 임베딩 좌표를 하나의 파일에 저장
- h5mu: 멀티오믹스 데이터 형식. 여러 modality(RNA, ATAC 등)를 하나의 파일에 통합
- AnnData: h5ad의 Python 객체.
adata.obs(세포 정보),adata.var(유전자 정보),adata.X(발현 매트릭스)로 구성 - Scanpy 워크플로우: QC → 정규화 → 고변동 유전자 선택 → PCA → UMAP → 클러스터링 → 세포 유형 주석
- 바이브 코딩의 핵심: 분석 파이프라인의 각 단계가 왜 필요한지를 이해하고, AI에게 단계별로 지시하는 것